Kaukatcr: an experiment in language design for multi-dimensional spaces
Kaukatcr: an experiment in language design for multi-dimensional spaces
One of the various projects associated with Project Xanadu™[1] was ZigZag™, a kind of organizer system or mind-mapping tool built around twisted multi-dimensional spaces called ZZStructures.
From the beginning, we wanted to make this system scriptable. Some existing internal implementations supported scripting in conventional languages, and Ted wanted a spreadsheet-formula-like language (since he thought of a ZZStructure as a kind of spreadsheet whose rows and columns were set free from their grid and tangled up in arbitrarily expressive ways).
When I was there, Jon Kopetz and I came up with the concept of a language that took more full advantage of the structures available, and I wrote a proof-of-concept implementation. It was not persued further — the language wasn’t really accessible to non-programmers the way a formula system might be, and we had other priorities — but I consider some of the ideas valuable, since, for all its limitations, it sits at the intersection of literate programming, stack programming, and visual programming.
Quick legal note
Project Xanadu produces a lot of code internally — a lot more than ever gets released — and a lot of internal documents and discussions. The code I’m linking to was written independently, from memory, based on things that I wrote for Xanadu. However, it is not officially blessed by the project, so the various trademarks (Project Xanadu™, ZigZag™, the flaming X logo, and probably others) don’t apply. As far as I am aware, this material does not violate any trade secrets — all trade-secrets related to ZigZag™ that I was privy to have been made public. Also, while patents related to this tech were filed, to my knowledge no applicable patents are currently in force.
From now on, I will refer to ZigZag™-like systems as ZZ. These ideas do not necessarily rely upon all of the features of ZigZag™, but may be applied to any system based on a ZZStructure. Also, I hate typing trademark slugs.
A crash course in ZZStructures and ZZ interface conventions
A ZZStructure is a collection of ‘cells’ — objects containing a value and a string-keyed associative array of pairs of pointers to other cells.[2]
A programmer might conceptualize a cell as the intersection of arbitrarily-many doubly-linked lists, each with a name. Alternately, they might see a cell as a point in a tangled multi-dimensional space (hence why the names given to these lists are called “dimensions”).
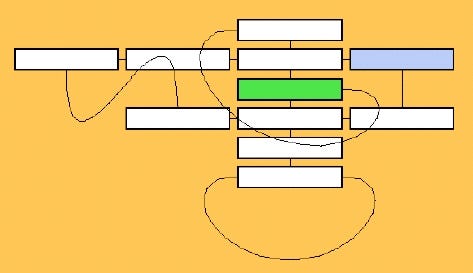
A full ZZStructure implementation can be written in 200 lines of python. For the sake of explanation, here is an even-more-simplified version:
cells=[]
class ZZCell:
def __init__(self, value=None):
global cells
self.cid=len(cells)
self.value=value
self.connections={}
self.connections[True]={}
self.connections[False]={}
cells.append(self)
# core operations
def getValue(self):
""" get cell's value. Use this, rather than the value attribute, unless you specifically don't want to handle clones """
return self.cloneHead().value
def getNext(self, dim, pos=True):
if dim in self.connections[pos]:
return self.connections[pos]
return None
def insert(self, dim, val, pos=True):
""" like setNext, except it will repair exactly one connection """
if(dim in self.connections[pos]):
temp=self.connections[pos][dim]
self.setNext(dim, val, pos)
val.setNext(temp, val, pos)
else:
self.setNext(dim, val, pos)
def breakConnection(self, dim, pos=True):
if self.getNext(dim, pos):
temp=self.connections[pos][dim]
temp.connections[not pos][dim]=None
self.connections[pos][dim]=None
def clone(self):
""" create a clone """
c=ZZCell()
self.rankHead("d.clone", True).setNext("d.clone", c)
return c
def cloneHead(self):
return self.rankHead("d.clone")
# underlying operations (usually not exposed through the UI)
def setNext(self, dim, val, pos=True):
self.connections[pos][dim]=val
val.connections[not pos][dim]=self
def rankHead(self, dim, pos=False):
""" Get the head (or tail) of a rank """
curr=self
n=curr.getNext(dim, pos)
while(n):
if(n==self):
break # handle ringranks
curr=n
n=curr.getNext(dim, pos)
return curr
def getDims(self):
return list(set(self.connections[True].keys() + self.connections[False].keys()))
Generally speaking, a conventional ZZ interface (a “view”) will consist of two panes, each with a particular cell selected and with two or three dimensions mapped to the spacial dimensions of the pane. Users navigate both panes simultaneously, or use each pane to view different aspects of the same cell (in the form of connections along different dimensions).
This article will be illustrated with hand-drawn images of a simplified ZZ interface of this type. ZZ keybindings and interactions are beyond the scope of this article, although I encourage those interested to read the official documentation in the ‘starter kit’ and watch the demonstration video.
Kaukatcr
Kaukatcr (pronounced “cowcatcher”[3]) is a stack-based language modeled loosely on Forth. It avoids tokenization by treating cell boundaries as word boundaries. Like Forth, any word that is neither a built-in nor found in the dictionary of defined functions will be treated as data and pushed onto the stack.
Kaukatcr has an ‘interpreter head’ — a cell that corresponds to the beginning of the program. The stack hangs off the interpreter head along the dimension ‘d.stack’ ; the names of defined functions hang off it along ‘d.funcs’; the call stack hangs off it along ‘d.call’; the interpreter iterates along ‘d.exec’.
Function definitions hang off their names along ‘d.exec’. ‘d.branch’ points to the targets of conditional jumps.
By convention, we hang comments off of our code along ‘d.comment’.
For the sake of readability for non-Forth-programmers, a few Forth keywords have been renamed: ‘:’ becomes ‘def’ and ‘;;’ becomes ‘end’.[4] Function definition, nevertheless, works approximately the same way:
: 2dup swap dup rot dup ;;
becomes:
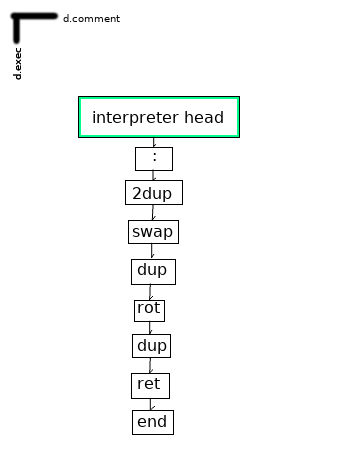
The ‘ret’ is required because we do not automatically return from calls when they exit — without the ‘ret’, the program will terminate when it walks off the end of a rank. This makes it a little easier to exit a program early, and so supports interactive editing — one can observe the stack during execution of an unfinished program, perhaps edit it, and then resume at an exit point.
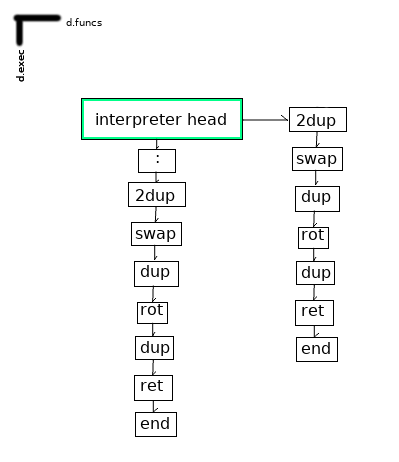
Once the code defining that function has been read, our interpreterHead will look like this:
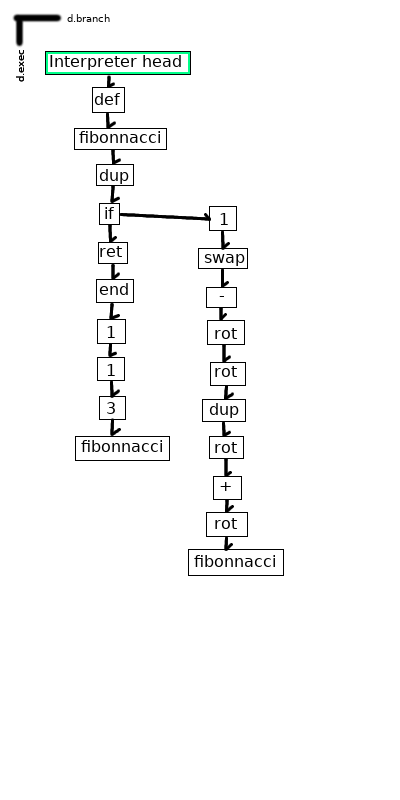
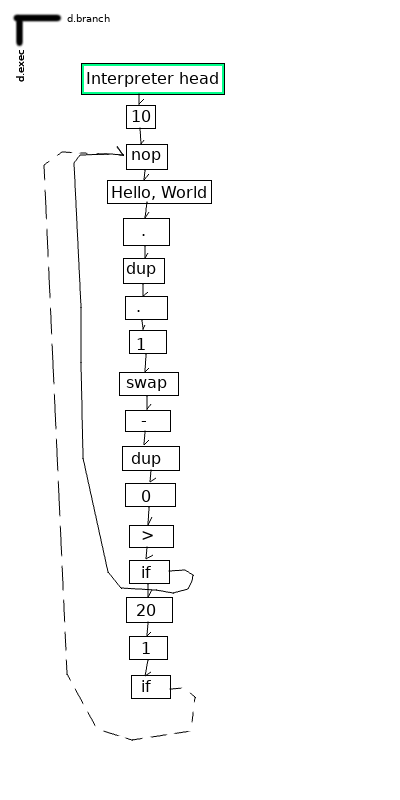
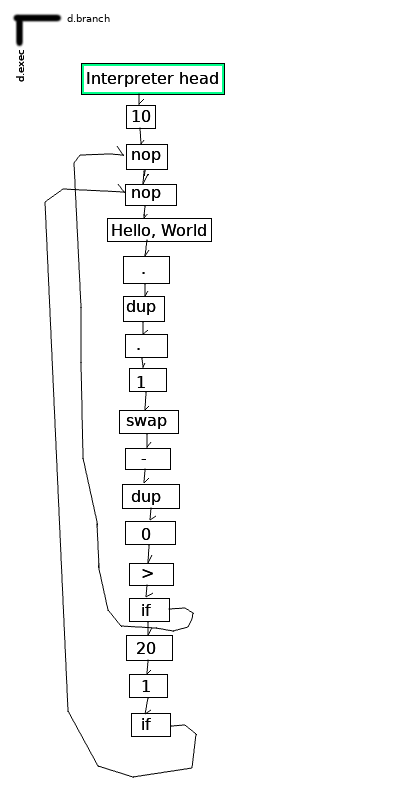
Finally, here’s an example with both functions and conditional branches:
Differences from Forth
Despite borrowing some syntax and conventions from Forth, there are fundamental differences (even beyond tokenization, which is not configurable in kaukatcr).
One difference is that builtins are not overridden by defined words with the same name. In the reference implementation, user defined function lookup is so much slower than builtins lookup that performing it on every step would be unreasonable for large programs. Furthermore, while redefining builtins is very powerful, it makes the most sense in a system that can easily have its state reset (to revert all possible breaking changes), while ZZ implementations theoretically should be image-based systems (like smalltalk VMs) where every change is automatically saved to persistent state. (Few-to-none of the actual implementations do this, but all of them are supposed to, according to design specs.)
Another difference is that ‘if’, being non-linear, doesn’t come with ‘else’ and ‘endif’ and friends — instead, it’s essentially a conditional branch. It operates equivalently to the ‘jnz’ instruction in x86 assembly. As a result, ‘if’ can be modified to act as an arbitrary ‘goto’ — just push 1 onto the stack before an if, and you can jump unconditionally to anywhere in the code.
In the current implementation, because we jump to the linked cell instead of the clonehead[5] of the linked cell, each cell can be the entrance point for at most one direct branch — however, I see no reason this couldn’t be an implementation-dependent or dialect-dependent decision. Limiting jump points in this way makes analyzing certain structures easier since they collapse into well-defined loops, but circumventing this in order to jump to a particular point from many places involves injecting a bunch of no-op instructions, which should be avoided.[6]
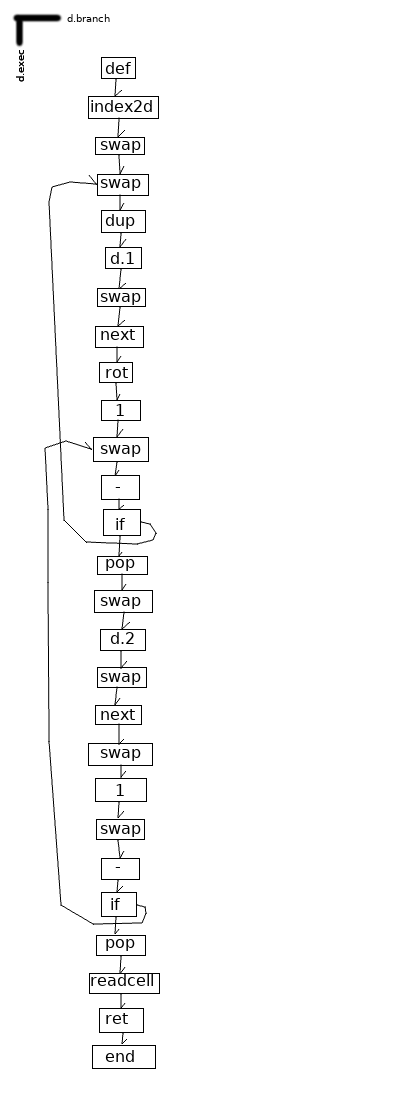
A third difference is the manipulation of larger data structures. Since all data is either ZZ cells, clones of ZZ cells, or strings or numbers stored in ZZ cells[1], and because ZZ navigation is exposed, it’s natural to use ranks as 1d arrays and to use cells with known sets of dimensions hanging off of them as associative arrays. For multidimensional arrays, I recommend using the convention of d.1, d.2, …, d.n and navigating those structures in the order of the cardinal dimension (i.e., to navigate to (3, 5, 7) we would go three steps along d.1, five steps down d.2, and then seven steps across d.3) — although obviously Kaukatcr is not a good choice for complex matrix arithmetic.
Footnotes
[1] Project Xanadu™ is the original hypertext project, formed in 1960 and still going. I worked there, in a volunteer capacity, from 2011 to 2016. It’s the brainchild of Theodor “Ted” Nelson. I recommend looking at the official website for more details.
[2] To be more accurate, a collection of cells is called a ‘slice’, and a ZZStructure may be composed of one or more slices. The module, as defined, only supports one slice (the ‘cells’ array at module scope). In other implementations, there is a slice class, which handles cell creation, garbage collection, serialization, and the allocation of cell IDs; however, I thought this might be too confusing for people unfamiliar with the concepts I’m trying to introduce. Anyhow, supporting multiple slices is mostly interesting because of the ability to link across slice boundaries — the mechanisms for which were at one time under trade secret. While I believe those trade secret protections are now void, I’m erring on the side of caution by avoiding detailed descriptions or implementations of them.
[3] The cowcatcher is the wedge-shaped construction found at the front of steam trains. It was invented by Charles Babbage, who also invented the stored-program mechanical computer. We chose this name because of this, and because the movement of the instruction pointer in two dimensions reminded us of a train following tracks. ‘Kaukatcr’ is the phonetic representation of ‘cowcatcher’ in the most popular lojban orthography.
[4] Some of my examples used ‘:’ by accident. So, I believe, did the internal prototype I initially developed. I have modified the implementation to support Forth-style word definitions. Writing and modifying this kind of code is very easy to do with a real zigzag interface, but quite awkward in GIMP!
[5] The ‘clonehead’ is the original from which some cell is cloned, if the cell in question is a clone. Mechanically, cloning works in ZZ by creating a rank of blank cells hanging off the original along d.clone — so, the clonehead is the head of the rank along d.clone. When we get the content/value of a cell, we automatically forward that content request to the clonehead, so from a UI perspective (and the perspective of anything that ‘reads’ the content of a cell) a clone contains the same content as the original.
[6] As you can see from the example, dereferencing clones makes certain kinds of code easier to write, but it has ramifications both for how function definition works (since currently it just clones the original function source) and for the regular use of the system. In particular, a user of a ZZ system might expect to be able to clone pieces of data from other programs or from non-code portions of his slice into his code in order to manipulate it, and dereferencing will break this behavior in potentially confusing ways.